Creators can't see their own patterns.
If you make content on Instagram, the advice you get is either generic — "post consistently, use hooks, add a CTA" — or it's expensive, the kind agencies sell. Neither tells you what's actually happening across your own videos. What you keep returning to. Who, specifically, is on the other side of the camera when you press record.
I wanted to know if a multimodal model could do that work for me. So I gave Gemma 4 twelve of my reels and asked it to read them — not the captions, the videos themselves — and tell me what I was making.
I ended up building a prototype that analyzed my Instagram reels, identified the through-line in my content, and reframed who I was making it for.
Two stages: extract, then reason.
The pipeline runs in two distinct passes. Stage one is per-reel extraction: each video goes through six to eight focused passes that pull out hooks, pacing, visual quality, audio cues, on-screen text, and the moment-to-moment structure of the clip. Each reel produces a structured JSON sidecar.
Stage two is cross-reel meta-analysis. With every video reduced to structured signals, the model can now reason across the whole corpus — finding content clusters, picking up voice, correlating what works with what gets ignored. The split matters: extraction is cheap and parallelizable, reasoning is where the strategy actually lives.
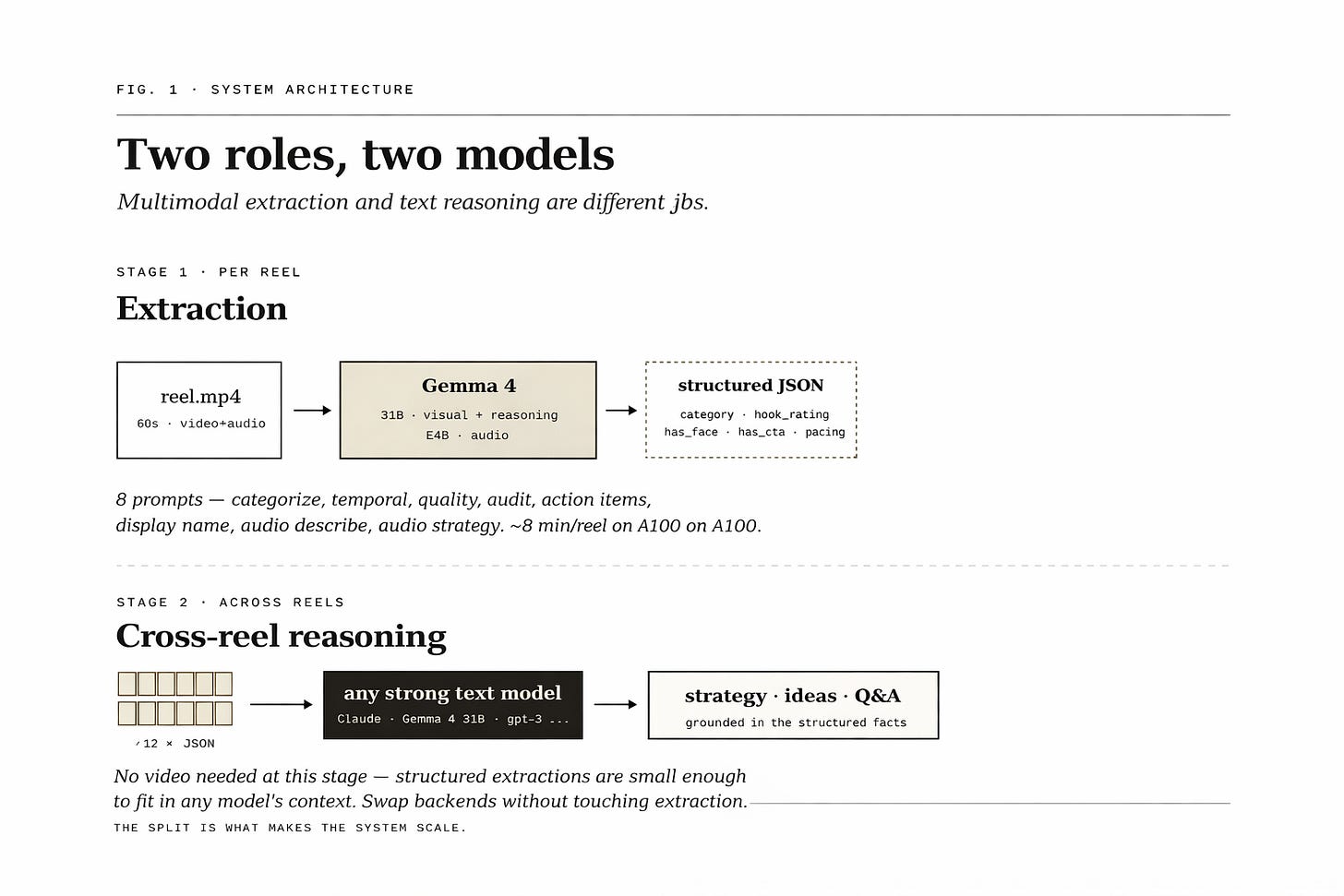
Two variants of Gemma 4, one job each.
Gemma 4 ships in multiple variants. The 31B model handles video — heavier, slower, but it's the one that can actually watch a clip and tell you what's in it. The smaller E4B model handles audio, transcription, and the lighter signal extraction. Both run locally on a single A100 80GB.
All outputs are structured JSON. That's the design choice that makes the second stage possible — once everything is structured, the cross-reel pass can correlate features, cluster reels, and produce strategy with citations back to specific videos.

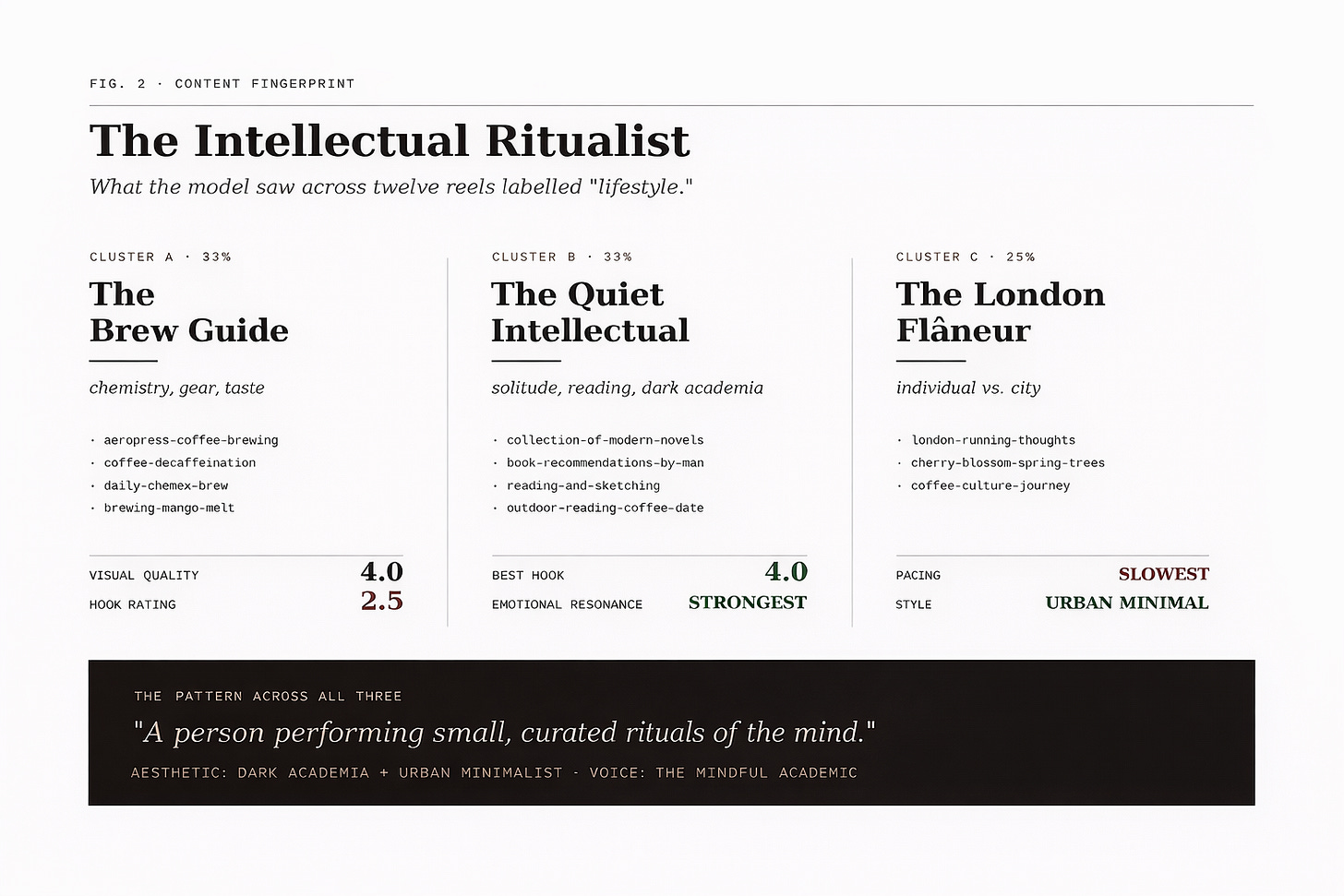
The intellectual ritualist.
I expected a list of stats. What I got was a reframing. Across twelve reels, the model identified three content clusters, found a consistent voice underneath them, and named the audience: The Intellectual Ritualist — someone who performs curated rituals of the mind. Coffee, books, slow mornings, deliberate gestures.
It also flagged what wasn't there: zero call-to-actions across all twelve reels. And instead of suggesting the generic "ask viewers to comment", it proposed persona-aligned alternatives — asking about brewing preferences, asking what they're reading, the kind of prompt that belongs to the ritual rather than interrupting it.
What the pipeline does.
Per-reel extraction
Six to eight focused passes per video — hooks, pacing, visual quality, audio cues, on-screen text. Structured JSON output per reel.
Cross-reel meta-analysis
Reasoning across the full corpus to find content clusters, voice, and correlations between features and engagement.
Conversational Q&A
A layer on top of the analysis that lets you ask follow-up strategy questions — grounded in the specific reels, not generic templates.
Persona-aligned suggestions
Strategy that belongs to your voice — call-to-actions, hooks, and prompts shaped by the audience the model has identified.